Published by
Opsolute Team
on

Introduction
Observability budgets have reached a breaking point. With 96% of IT leaders maintaining or increasing monitoring spend and costs growing faster than value delivered, engineering teams face a critical challenge: how do you achieve comprehensive system visibility without bankrupting your cloud budget? The answer isn't collecting less data but monitoring smarter. Cost-intelligent monitoring represents a fundamental shift from reactive cost-cutting to strategic optimization, enabling organizations to maintain full observability while reducing expenses by 50-72% through architectural improvements, intelligent data management, and AI-driven automation.
Key Highlights
96% of organizations are maintaining or increasing observability spending in 2026
Enterprise observability spending increased 212% between 2019 and 2023
Organizations adopting intelligent strategies report 50-72% cost reductions
97% of IT decision-makers are actively managing observability costs
Only 41% of leaders are satisfied with their tools' ability to generate actionable intelligence
84% of companies are pursuing unified platforms to reduce complexity and costs
The Observability Cost Crisis: Why Traditional Monitoring Becomes Unsustainable
Cloud-native architectures generate exponentially more telemetry data. Every microservice, container, and serverless function emits metrics, logs, and traces. The result? Observability costs that double annually while providing diminishing returns.
Traditional monitoring tools charge per data volume. Send 10TB of logs monthly? That's your baseline cost. Scale to 20TB? Your bill doubles. This pricing model punishes success and growth, forcing teams into impossible choices between comprehensive visibility and budget constraints.
The gap between spending and value widens every quarter. Teams discover they're paying premium prices for data they never query, storing telemetry that provides no actionable insights, and maintaining redundant collection pipelines that duplicate effort. When month-end bills arrive, finance demands cuts. Engineering scrambles to reduce data volume without creating blind spots.
Most organizations respond with desperate measures. They sample aggressively, reduce retention windows, and limit environment coverage. These approaches save money short-term but create critical gaps in visibility. When incidents occur in unmonitored environments or fall within sampling gaps, teams lose hours reconstructing what happened from incomplete data.
Understanding Cost-Intelligent Monitoring: Beyond Simple Cost Reduction
Cost-intelligent monitoring flips the equation. Instead of asking "what data can we eliminate?" it asks "what telemetry provides genuine value?"
This approach combines three pillars: intelligent sampling that captures anomalies while filtering routine data, tiered storage architectures that match cloud cost control to access patterns, and AI-driven analytics that automatically identify optimization opportunities. Together, these techniques maintain comprehensive visibility while dramatically reducing infrastructure costs.
The key difference? Traditional cost-cutting reduces capability. Cost-intelligent monitoring increases efficiency. Teams move from 5% trace coverage with basic sampling to 100% anomaly detection with intelligent approaches. They maintain full retention requirements while reducing storage costs by orders of magnitude. They achieve better visibility at lower cost.
Traditional Approach | Cost-Intelligent Monitoring |
Sample all data uniformly | Capture 100% of anomalies, sample baseline |
Single-tier storage | Hot/warm/cold tiered architecture |
Vendor lock-in pricing | Open standards, flexible backends |
Manual optimization | AI-driven continuous improvement |
Trade coverage for cost | Improve visibility while reducing spend |
The Dangerous Cost-Cutting Approaches Teams Must Avoid
Aggressive data sampling creates blind spots that mask critical issues. Teams sample 90% of traces to reduce volume, then miss the 0.1% of requests that indicate emerging problems. By the time patterns become obvious, incidents have escalated.
Limited environment monitoring represents false economy. Teams instrument production thoroughly but skimp on staging and development. When issues arise in production, they lack comparative data from other environments to isolate root causes. Debugging takes hours instead of minutes.
Reduced retention windows force impossible trade-offs. Teams keep recent data for debugging but delete historical context needed for trend analysis and capacity planning. When finance asks "why did costs spike last quarter?" the telemetry data no longer exists to answer.
These approaches share a common flaw: they sacrifice observability capability to hit cost targets. Short-term savings create long-term technical debt. Incident response slows. Mean time to resolution increases. Customer experience suffers. The hidden costs dwarf the apparent savings.
Intelligent Sampling: Capturing What Matters Without Losing Critical Signals
Modern sampling techniques distinguish between signal and noise. Machine learning models establish baseline behavior for each service, then flag deviations for 100% capture. Routine requests that match patterns get sampled aggressively. Anomalies, errors, and edge cases? Captured completely.
Head-based sampling makes decisions at trace initiation. When a request enters your system, the sampler determines whether to instrument the entire transaction path. This works well for known patterns but can miss issues that only become apparent downstream.
Tail-based sampling waits until transactions complete before deciding what to keep. The system sees the full transaction context, identifies anomalies or errors, then retroactively stores relevant traces. This captures problems that head-based approaches miss while maintaining aggressive sampling of routine traffic.
Dynamic rate adjustment responds to system conditions in real time. During normal operations, sampling rates stay high to minimize storage. When error rates climb or latency spikes, rates automatically decrease to capture more context. Teams get detailed visibility exactly when they need it.
Organizations implementing intelligent sampling report moving from 5% trace coverage to 100% anomaly detection while reducing data volume 50-95%. The key? Storing exceptions instead of routine behavior creates comprehensive coverage at minimal cost.
Tiered Storage Architecture: Matching Cost to Data Value
Not all telemetry data has equal value over time. Recent data supports active debugging. Mid-term data enables trend analysis. Long-term data satisfies compliance requirements. Tiered storage architecture matches storage cost to access patterns at each lifecycle stage.
Hot storage holds the most recent 7-30 days. This data resides on fast SSDs optimized for query performance. Engineers query this tier constantly during incident response and debugging sessions. The premium storage cost is justified by high access frequency and real-time requirements.
Warm storage contains data from 30-90 days ago. This tier uses compressed storage with slightly slower query performance. Teams access this data for trend analysis, capacity planning, and retrospective investigations. The moderate cost reflects reduced but still-regular access patterns.
Cold storage archives data beyond 90 days. Compliance requirements often mandate year-long or multi-year retention, but teams rarely query historical telemetry. This tier leverages inexpensive object storage like S3 Glacier, reducing costs by 90%+ versus hot storage while maintaining data availability for regulatory purposes.
The cost impact is dramatic. Storing 100TB entirely on hot storage costs $23,000 monthly. Implementing tiered storage with 10TB hot, 30TB warm, and 60TB cold reduces costs to $4,800 monthly. Same data volume. Same retention. 79% cost reduction through architectural improvements.
Observability Budgets: Implementing FinOps Principles for Monitoring
Observability budgets establish telemetry volume limits tied to business value. Instead of unlimited data collection, teams receive allocations based on service criticality, traffic volume, and revenue impact. This forces prioritization of data that detects failures or improves performance.
Platform engineering teams enforce budgets through pre-deployment cost gates. Before services deploy to production, automated checks verify their telemetry configuration stays within allocated limits. Deployments exceeding budgets require explicit approval and justification, preventing runaway costs from reaching production.
Modern FinOps platforms integrate observability spending with broader cloud cost management. Teams can set budget guardrails across multiple dimensions—by account, environment, team, or product—with real-time enforcement and threshold alerts. This proactive approach prevents budget breaches before they happen rather than discovering overages at month-end.
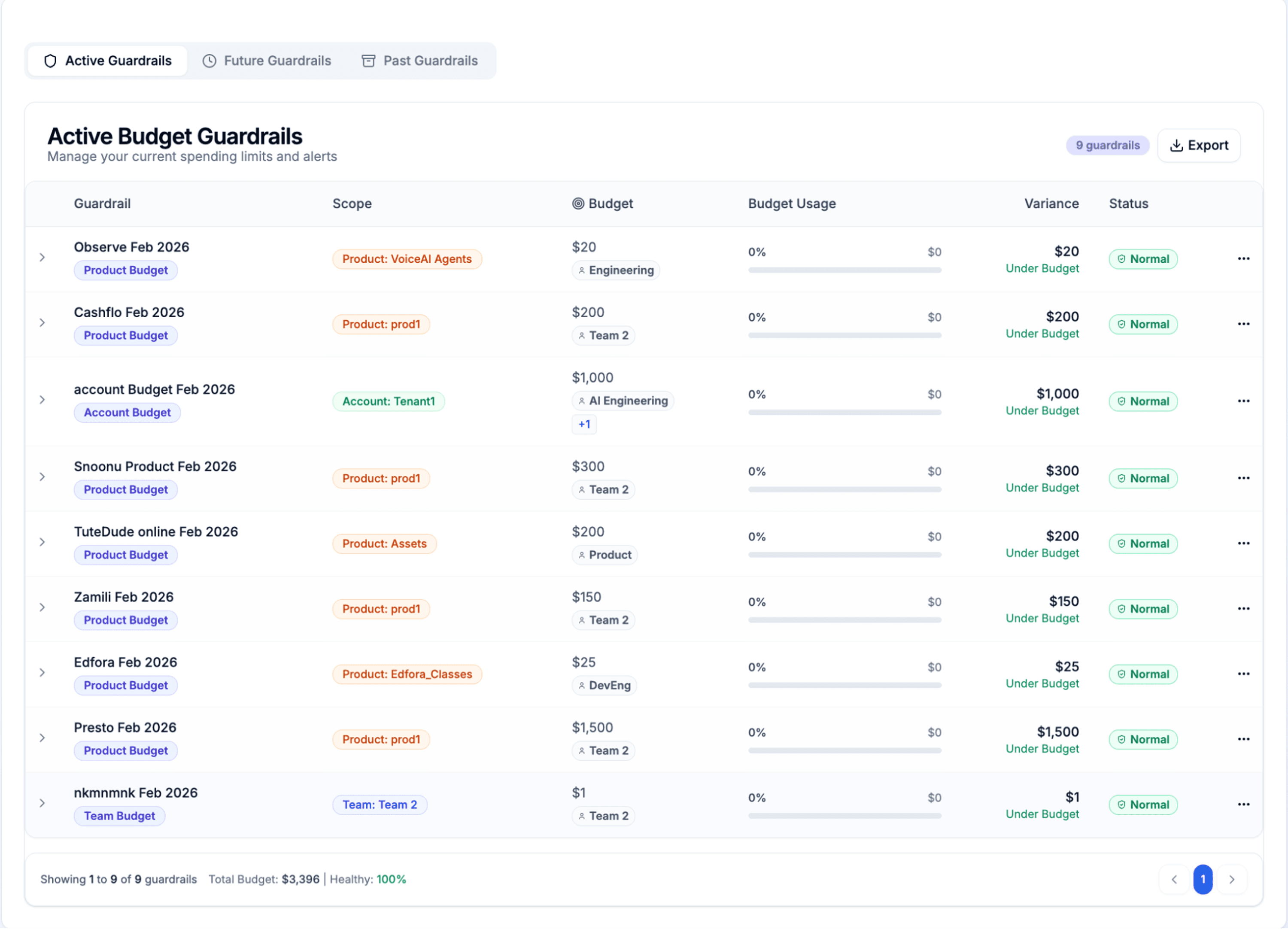
Chargeback models drive accountability by attributing observability costs to specific teams. When engineering teams see their monitoring expenses on monthly reports, behavior changes rapidly. Teams optimize instrumentation, reduce noise, and focus on high-value telemetry. Cost awareness becomes cultural.
Organizations implementing observability vs monitoring budgets report 40-60% cost reductions in the first quarter. Teams discover that unlimited observability encourages lazy instrumentation. Constraints force intentional decisions about what truly needs monitoring.
OpenTelemetry and Vendor Neutrality: Breaking the Cost Lock-In
Proprietary monitoring vendors create cost traps through closed ecosystems. Once telemetry data enters their platform, extracting it requires expensive custom integration. Pricing models obscure true costs until bills arrive. Switching vendors means rewriting instrumentation across your entire codebase.
OpenTelemetry provides an exit strategy. This vendor-neutral standard separates telemetry collection from storage and analysis. Applications instrument once using OpenTelemetry libraries, then route data to any compatible backend. Teams gain flexibility to optimize costs without touching application code.
Multi-backend routing enables sophisticated cost strategies. Send high-priority traces to premium vendors with advanced analysis capabilities. Route routine logs to cost-effective open-source solutions. Archive compliance data to object storage. Each telemetry type flows to the most cost-effective destination for its use case.
Organizations adopting OpenTelemetry report 50-72% cost reductions by escaping vendor lock-in. A financial services company reduced observability spending from $840K to $235K annually by routing telemetry to self-hosted ClickHouse instead of premium SaaS vendors. Same visibility. Different economics.
The migration requires upfront investment. Teams instrument applications with OpenTelemetry libraries and deploy collection infrastructure. But the payback period averages 4-6 months, with ongoing savings compounding annually as data volumes grow.
AI-Driven Cost Optimization: Autonomous Resource Management
AI-powered observability platforms analyze workload patterns continuously. They identify cost optimization opportunities humans miss: redundant metrics, unused data streams, oversized retention windows, and inefficient query patterns. These insights drive automatic optimization without manual intervention.
Predictive rightsizing uses historical data to forecast future telemetry volumes. When the system detects sustained usage below provisioned capacity, it automatically scales down infrastructure. When patterns indicate increasing load, it scales up before performance degrades. Resources match actual requirements continuously.
Anomaly-based alerting replaces static thresholds with machine learning models. Instead of alerting when metrics exceed predefined values, AI identifies deviations from learned baselines. This reduces alert noise by 80-90% while improving incident detection accuracy. Teams spend less time investigating false positives.
Advanced platforms now integrate cloud cost optimization recommendations directly into cloud resource management. When anomalous spending patterns emerge—whether from observability tools or the infrastructure being monitored—automated systems can identify idle resources, suggest rightsizing opportunities, and even calculate potential savings before implementation.
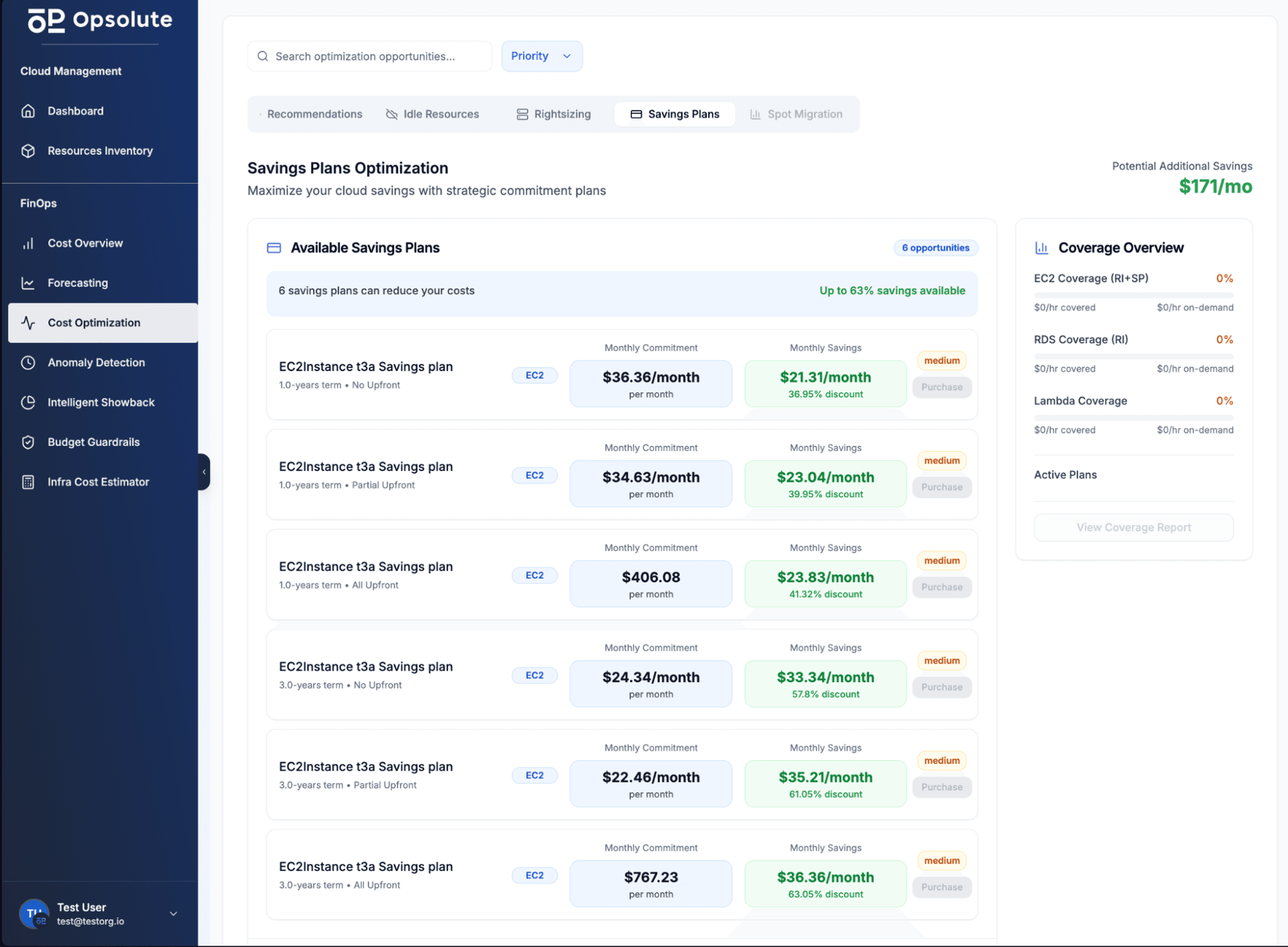
The cost impact extends beyond observability itself. Organizations implementing AI-driven optimization report 30-75% reductions in cloud infrastructure costs as autonomous agents optimize resource allocation based on actual usage patterns learned from telemetry data.
Unified Observability: Consolidating Tools to Reduce Complexity and Cost
Tool sprawl creates unnecessary overhead and integration complexity that drives up costs. Organizations running separate platforms for metrics, logs, traces, and infrastructure monitoring face duplicated data collection, inconsistent correlation, and multiple vendor relationships to manage.
Unified observability platforms consolidate these capabilities into single systems that collect, store, and analyze all telemetry types together. This consolidation delivers immediate cost benefits: eliminate duplicate collection agents, reduce vendor licensing fees, and simplify operational overhead.
The 84% of companies pursuing tool consolidation aren't just reducing complexity—they're enabling better analysis. When metrics, logs, and traces reside in the same system, teams correlate signals faster during incident response. A latency spike in metrics links directly to error logs and distributed traces showing exactly which service caused the issue.
Consolidated platforms also simplify cost attribution and management. Instead of tracking spending across five different observability vendors, teams manage a single system with unified pricing, centralized budget controls, and consistent cost allocation across teams and services. This visibility makes optimization decisions clearer and implementation faster.
Organizations completing consolidation projects report operational benefits beyond cost savings: 60-70% reduction in mean time to resolution, 50% fewer tools for teams to learn, and 40% less time spent on vendor management and contract negotiations.
Implementing Cost-Intelligent Monitoring: A Practical Roadmap for 2026
Start with a comprehensive cost audit. Analyze observability spending by tool, team, and data type. Identify the largest cost drivers. A typical enterprise discovers that 80% of costs come from 20% of data sources. These high-cost, low-value telemetry streams become optimization priorities.
Create a complete inventory of cloud resources and their monitoring configuration. Track which services generate the most telemetry, which data rarely gets queried, and where costs concentrate. Understanding your current state provides the baseline for measuring improvement and identifying quick wins.
Establish baseline metrics before implementing changes. Document current capabilities: incident detection time, query performance, data retention periods, and coverage gaps. These baselines prove that cost-intelligent monitoring improves rather than degrades observability.
Implement quick wins first. Eliminate idle resources consuming monitoring budget. Delete unused dashboards and alerts. Archive or delete telemetry data that no one queries. These actions require minimal effort but can reduce costs 15-25% within days.
Deploy intelligent sampling and tiered storage next. These architectural improvements deliver the largest cost reductions (50%+) but require more coordination. Start with non-critical services to validate approaches, then expand to production workloads as confidence builds.
Build observability budgets and chargeback into your roadmap. Set spending limits tied to service criticality and business value. Enforce limits through automated guardrails that prevent budget breaches. Attribute costs back to teams to drive accountability and optimization behavior.
Monitor cost efficiency continuously. Track telemetry volume per service, storage costs by tier, and query patterns over time. When costs creep upward, investigate immediately rather than waiting for month-end surprises. Cost-intelligent monitoring requires ongoing attention, not one-time fixes.
Consider platforms that unify cost management across both observability and cloud infrastructure. When budget tracking, anomaly detection, forecasting, and chargeback capabilities work together, teams gain complete visibility into where money flows and can optimize spending holistically rather than managing tools in isolation.
FAQ
Q: What is the difference between traditional monitoring and cost-intelligent monitoring?
Traditional monitoring focuses on collecting maximum data regardless of cost, while cost-intelligent monitoring strategically captures high-value signals using techniques like intelligent sampling, tiered storage, and AI-driven analytics. This approach maintains comprehensive visibility while reducing costs by 50-72%.
Q: Will intelligent sampling cause me to miss critical incidents?
Modern intelligent sampling uses machine learning to identify and retain anomalies, edge cases, and critical transactions at 100% coverage. Only baseline, routine data is sampled. Organizations report moving from 5% to 100% trace coverage using these techniques.
Q: How much can organizations realistically save with cost-intelligent monitoring?
Organizations implementing comprehensive strategies report 30-75% cost reductions. OpenTelemetry adopters achieve 50-72% savings, AI-driven optimization delivers 30%+ reductions, and architectural improvements like tiered storage reduce costs by orders of magnitude.
Q: What role does OpenTelemetry play in cost optimization?
OpenTelemetry breaks vendor lock-in by providing open standards for telemetry collection, enabling organizations to route data to cost-effective backends and avoid per-volume pricing premiums. It provides flexibility to optimize storage and processing costs independently.
Q: How do observability budgets work in practice?
Observability budgets set telemetry volume limits per team or service, tied to business value. Platform teams enforce these through pre-deployment cost gates and chargeback models. Teams prioritize data that detects failures or improves performance.
Q: Should we reduce observability coverage to save costs?
No. Reducing coverage creates dangerous blind spots that delay incident response and compromise security. Cost-intelligent monitoring maintains full coverage while optimizing how data is collected, stored, and processed.
Q: What is the first step to implementing cost-intelligent monitoring?
Start by auditing current observability spending to identify cost drivers. Analyze which data provides value versus noise, establish baseline metrics, and prioritize quick wins like eliminating idle resources before tackling architectural improvements.
Take Control of Observability Costs Today
Cost-intelligent monitoring transforms observability from a budget liability into a strategic advantage. By implementing intelligent sampling, tiered storage, and AI-driven optimization, organizations achieve comprehensive visibility at sustainable costs. The shift requires upfront investment in new architectures and practices, but the payback period averages 4-6 months with ongoing savings compounding annually.
Start small. Audit your current spending. Implement quick wins. Build momentum with measurable cost reductions. Then tackle larger architectural improvements that deliver transformational savings. The organizations that master cost-intelligent monitoring in 2026 will maintain competitive advantage through superior system visibility while their competitors struggle with unsustainable budgets.
Ready to optimize your observability costs? Schedule a FinOps assessment to identify immediate opportunities in your infrastructure.
Stop guessing what your AWS bill will be next quarter.
Connect your AWS Organization in under 30 minutes. Most customers see their first chargeback report in 14 days and realize a 5–10× return on Opsolute within 90 days.
