Published by
Opsolute Team
on
Introduction
Infrastructure outages cost enterprises over $1 million per hour in 2026, yet 40% of organizations admit they lack clear visibility into their cloud configurations. As 83% of enterprises now operate multi-cloud strategies spanning AWS, Azure, and GCP, traditional monitoring approaches create operational blind spots that expose critical systems to downtime, security breaches, and runaway costs. This guide reveals how modern cloud monitoring transforms reactive firefighting into proactive infrastructure intelligence that prevents issues before they impact operations.
Key Highlights
Cloud monitoring provides real-time visibility across infrastructure, applications, security posture, and cost attribution in distributed environments
Organizations achieve 79% lower downtime and 4x median ROI (roughly 300%) through full-stack observability versus fragmented monitoring tools
Multi-cloud complexity demands AI-driven anomaly detection, predictive analytics, and intelligent automation to prevent incidents
Critical metrics include CPU utilization, memory consumption, network latency, error rates, security events, and granular cost tracking
Successful monitoring combines automated alerting, continuous compliance scanning, cross-team collaboration, and strategic FinOps integration
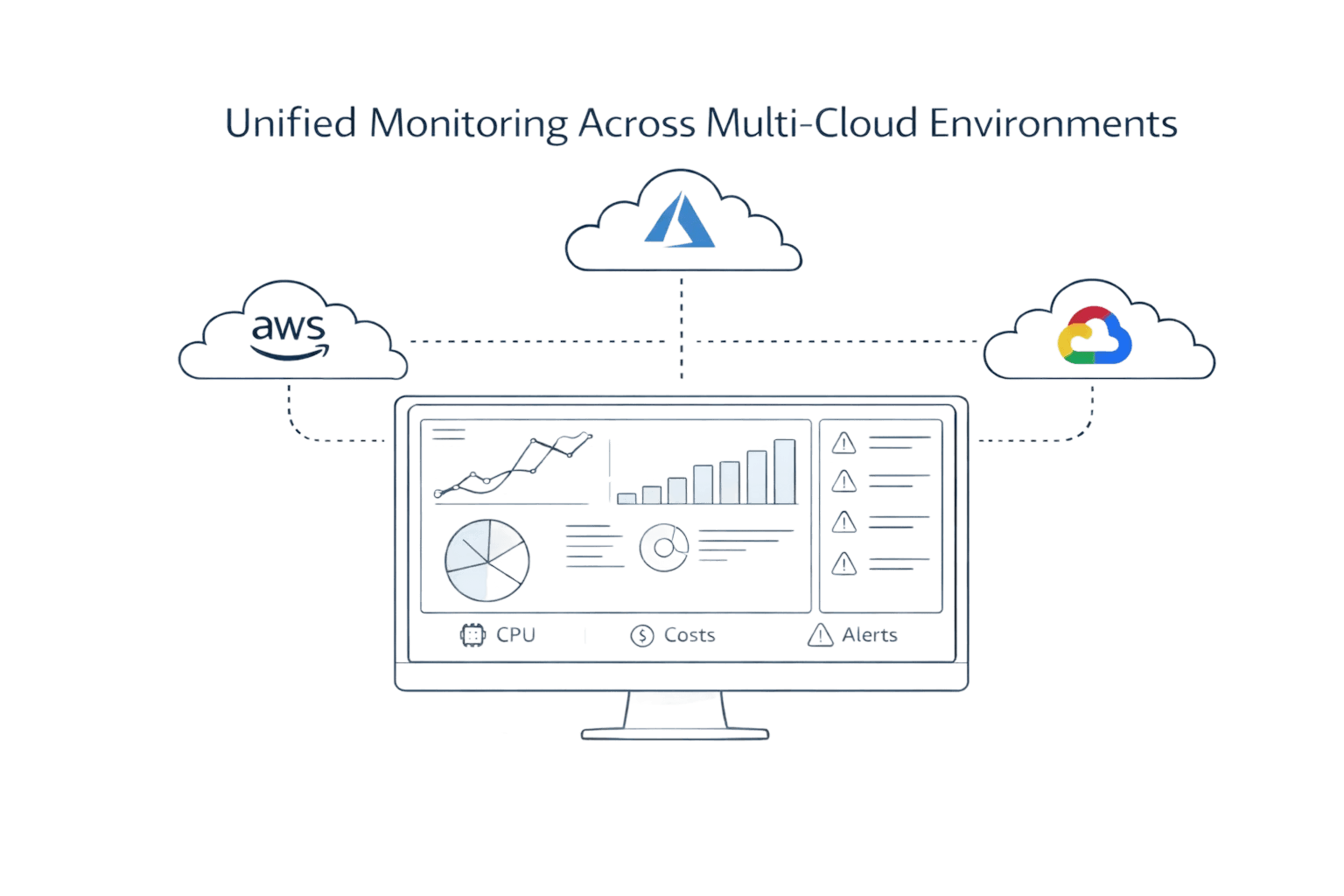
Understanding Cloud Monitoring: What It Is and Why It Matters
Cloud monitoring is the continuous observation and analysis of cloud infrastructure, applications, and services to ensure optimal performance, security, and cost efficiency. Unlike traditional infrastructure monitoring focused on static servers, modern cloud monitoring addresses dynamic, distributed architectures where resources scale automatically and workloads move between providers.
The shift matters because cloud failures have direct business impact. High-impact outages carry median costs of $2 million per hour, with some organizations experiencing downtime expenses that reach $33,333 per minute. When monitoring catches anomalies early, teams prevent cascading failures that damage revenue, customer experience, and brand reputation.
What makes cloud monitoring unique is its scope. You're not just watching CPU usage on a few servers. You're tracking ephemeral containers that live for seconds, serverless functions that execute without persistent infrastructure, microservices dependencies across multiple clouds, API latency across global regions, security postures that shift with every deployment, and costs that fluctuate hourly based on consumption patterns.
The monitoring market reflects this complexity. Valued at $3.75 billion in 2025, the cloud monitoring sector is expected to reach $9.30 billion by 2030, growing at 19.91% annually. This acceleration stems from enterprises recognizing that visibility isn't optional when most of their workloads run in cloud environments.
The Multi-Cloud Monitoring Challenge in 2026
Multi-cloud adoption crossed a tipping point. By 2026, 93% of organizations have adopted multi-cloud strategies, utilizing an average of 4.8 different clouds, with 43% of financial services firms already distributing workloads across multiple hyperscalers. Each provider exports unique metrics through different APIs, creating telemetry sprawl that fragments operational visibility.
The problem compounds when you consider that AWS holds 31% market share, Azure captures 24%, and Google Cloud commands 13%. Teams monitoring all three face inconsistent data formats, disparate dashboards, and incompatible alerting systems. Without unified platforms, engineers toggle between CloudWatch, Azure Monitor, and Google Cloud Operations, manually correlating data to understand system-wide issues.
This fragmentation creates dangerous blind spots. When a transaction spans on-premises databases, AWS compute, and Azure storage, piecing together the performance story requires correlating logs from three separate systems. By the time you identify the root cause, customers have already experienced degraded service.
The challenge extends beyond technical complexity. Finance teams need cost attribution across providers. Security teams must enforce consistent policies regardless of where workloads run. Compliance teams require unified audit trails. Each stakeholder demands different views into the same infrastructure, multiplying the monitoring burden.
Core Cloud Monitoring Components You Must Track
Effective cloud monitoring and cloud cost governance covers five critical dimensions that together provide comprehensive visibility into cloud operations.
Infrastructure metrics form the foundation. Track CPU utilization, memory consumption, disk I/O, network bandwidth, and storage capacity across compute instances, containers, and serverless functions. These metrics reveal resource constraints before they cause outages and identify over-provisioned resources wasting budget.
Application performance monitoring captures user-facing metrics. Response times, error rates, transaction volumes, and throughput measure how applications behave under load. Modern APM traces requests across distributed services, showing exactly where latency originates in complex microservices architectures.
Network health monitoring tracks connectivity, bandwidth utilization, packet loss, and latency between components. In multi-cloud environments, network monitoring reveals issues with inter-region communication, VPN tunnels, and direct connect circuits that impact application performance.
Security posture tracking monitors misconfigurations, unauthorized access attempts, policy violations, and vulnerability exposures. With 82% of data breaches involving cloud data, continuous security monitoring prevents incidents rather than just detecting them.
Cost management rounds out the monitoring picture. Track spending by service, region, team, and project. Monitor budget thresholds, identify idle resources, and forecast future costs. Observability ingestion itself can consume 15-25% of cloud spend, making cost monitoring essential for controlling expenses.
Monitoring Category | Key Metrics | Business Impact |
Infrastructure | CPU, memory, disk I/O | Prevents resource exhaustion |
Application | Response time, error rates | Ensures user satisfaction |
Network | Latency, bandwidth, packet loss | Maintains connectivity |
Security | Misconfigurations, access violations | Protects data and systems |
Cost | Spend by service, budget tracking | Controls cloud expenses |
Cloud Monitoring Best Practices for 2026
Start by setting clear KPIs aligned with business objectives. Don't monitor everything just because you can. Define service level objectives for critical transactions, establish acceptable error budgets, and determine which metrics directly impact customer experience or revenue.
Implement unified observability platforms that consolidate data from multiple sources. OpenTelemetry adoption rose sharply because vendor-neutral instrumentation enables consistent monitoring across heterogeneous environments. Unified platforms normalize metrics from AWS, Azure, and GCP, eliminating the need to correlate data manually across separate dashboards. The shift toward consolidated platforms is clear: 41% of organizations plan to consolidate monitoring tools within the next year, recognizing that unified visibility reduces complexity.
Establish intelligent alerting thresholds to combat alert fatigue. Traditional static thresholds generate noise. Use AI-driven anomaly detection that learns normal patterns and alerts only when behavior deviates significantly. Configure alerts based on business impact rather than technical metrics, ensuring notifications require human intervention rather than overwhelming teams with false positives.
Automate responses to common issues. When monitoring detects an idle resource, automatically terminate it. When traffic spikes exceed capacity, trigger auto-scaling. When security scans identify misconfigurations, remediate them through infrastructure-as-code pipelines. Automation reduces mean time to resolution while freeing teams for strategic work.
Conduct regular reviews of monitoring effectiveness. Analyze which alerts led to action, identify blind spots that missed issues, and refine thresholds based on lessons learned. Treat monitoring as a living practice that evolves with infrastructure rather than a one-time configuration.
Essential Tools and Technologies for Cloud Monitoring
Native cloud provider tools offer deep integration within their ecosystems. CloudWatch monitors AWS infrastructure comprehensively. Azure Monitor provides visibility across Azure services. Google Cloud Operations delivers observability for GCP workloads. These first-party tools excel for single-cloud environments but struggle with multi-cloud visibility.
Third-party unified platforms solve the multi-cloud challenge by aggregating data across providers. These vendor-agnostic solutions normalize metrics, consolidate dashboards, and enable consistent alerting regardless of where workloads run. Key features include auto-discovery of resources, customizable visualizations, AI-powered anomaly detection, and extensive integration capabilities.
When evaluating monitoring platforms, prioritize comprehensive metric coverage spanning infrastructure, applications, security, and costs. Ensure real-time data collection with minimal latency. Verify intelligent alerting that reduces noise. Check integration with existing tools like incident management, collaboration platforms, and CI/CD pipelines.
Scalability matters as environments grow. Solutions must handle dynamic resource counts without performance degradation. Look for consumption-based licensing that aligns costs with actual usage rather than penalizing density.
AI and Automation in Modern Cloud Monitoring
Artificial intelligence transforms monitoring from reactive detection to predictive prevention. AI-driven anomaly detection analyzes historical patterns across metrics, identifying unusual behavior that indicates emerging issues. These systems surface precursors to incidents before they escalate, giving teams time to investigate and remediate. Organizations deploying AI monitoring capabilities report higher overall business value and stronger ROI from their observability investments.
Predictive analytics enables proactive capacity planning. By forecasting resource demands based on historical trends, teams provision capacity ahead of need rather than reacting to exhaustion. This prevents performance degradation while avoiding over-provisioning that wastes budget.
Automated remediation workflows respond to detected issues without human intervention. When monitoring identifies an unhealthy instance, automation can restart services, failover to healthy nodes, or scale capacity automatically. Site Reliability Engineering practices now embed these golden signals into CI/CD pipelines, catching defects before production deployment.
Intelligent alert correlation reduces noise by grouping related events into single incidents. When a network issue affects 50 microservices, correlation surfaces one alert about network connectivity rather than flooding teams with 50 separate notifications. This dramatically reduces alert fatigue while accelerating root cause analysis.
Pro Tip: Start AI implementation with anomaly detection on critical services. Build confidence through validation against known incidents before expanding to automated remediation.
Security and Compliance Monitoring in Cloud Environments
Security monitoring in cloud environments focuses on continuous validation rather than periodic assessments. Automated scanning detects misconfigurations as they occur, preventing the majority of security failures that stem from configuration errors.
Identity and access management monitoring tracks authentication attempts, privilege escalations, and policy violations. With credential-based attacks accounting for 16% of breaches, continuous IAM monitoring catches unauthorized access before attackers move laterally.
Vulnerability scanning identifies exposed resources and unpatched systems. Continuous scanning catches security gaps before they can be exploited, enabling automated patching workflows that remediate vulnerabilities without manual intervention.
Compliance monitoring validates adherence to frameworks like GDPR, HIPAA, and PCI DSS. Automated reporting generates audit-ready documentation, streamlining regulatory reviews. As data sovereignty requirements intensify across regions, compliance monitoring ensures workload placement and data handling meet local regulations.
Threat intelligence integration correlates security events with known attack patterns. This context helps teams distinguish genuine threats from benign anomalies, prioritizing response efforts effectively.
Cost Optimization Through Effective Monitoring
Cloud monitoring directly impacts financial efficiency by revealing spending patterns, identifying waste, and enabling data-driven optimization. Cost attribution breaks down spending by team, project, environment, and service, creating accountability and enabling chargeback models. Research shows 80% of container spend is wasted on idle resources, highlighting the importance of monitoring-driven optimization.
Idle resource detection identifies compute instances, storage volumes, and databases consuming budget without delivering value. Automated monitoring flags resources with low utilization, enabling teams to rightsize or terminate them. Organizations typically discover 15-30% cost savings through idle resource elimination alone.
Rightsizing recommendations analyze utilization patterns to suggest appropriate instance types. When monitoring shows consistent 20% CPU usage on large instances, recommendations propose smaller types that meet actual demand while reducing costs.
Spending trend analysis forecasts future costs based on historical patterns. Teams budget accurately when they understand growth trajectories and seasonal variations. Budget threshold alerts warn when spending approaches limits, preventing overruns.
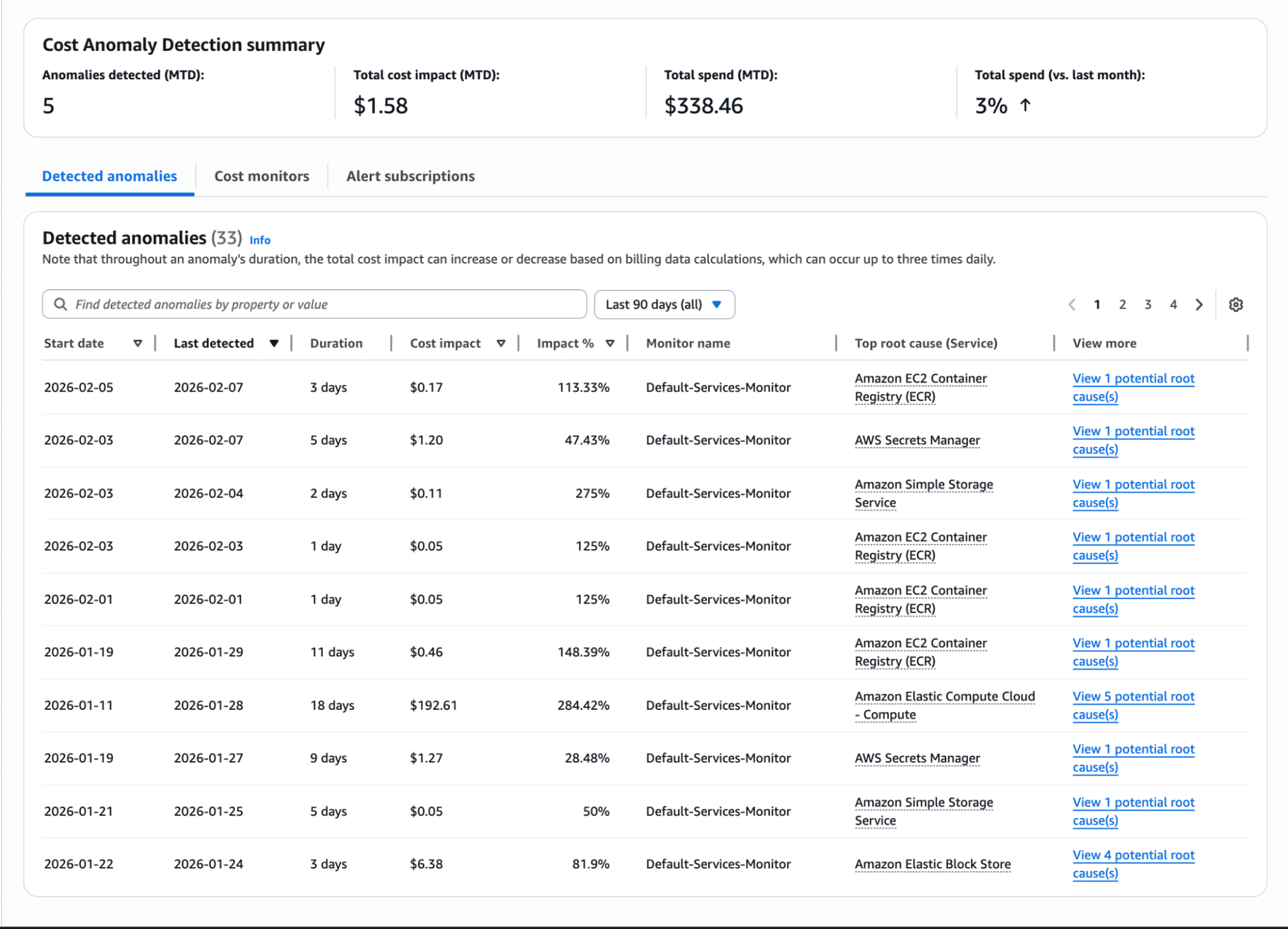
FinOps integration connects monitoring data with financial processes. Teams see not just technical metrics but the cost implications of their decisions. This visibility aligns engineering choices with business objectives, ensuring performance improvements justify their expense.
Building a Future-Ready Cloud Monitoring Strategy
Creating sustainable monitoring strategies requires treating visibility as an architectural decision rather than operational afterthought. Design systems with observability built in from the start, incorporating instrumentation into application code and infrastructure-as-code templates.
Plan for continuous improvement cycles that adapt monitoring to evolving needs. As architectures change, new services launch, and workload patterns shift, monitoring must evolve correspondingly. Regular assessment identifies gaps and opportunities for enhancement. The major cloud outages experienced in 2025 across Google Cloud, Microsoft 365, AWS, and other providers have driven enterprises to rethink resilience strategies, shifting monitoring from an operational afterthought to strategic investment.
Prepare for emerging technologies like edge computing and IoT that distribute workloads beyond traditional cloud regions. Monitoring strategies must extend to edge nodes, maintaining visibility regardless of where computation occurs.
Incorporate sustainability metrics as environmental accountability becomes strategic priority. Organizations are increasingly tracking cloud energy consumption alongside technical metrics, with sustainability monitoring expected to become mainstream in hybrid cloud environments.
Invest in team capabilities through training and knowledge sharing. Effective monitoring requires understanding what metrics matter, how systems behave under stress, and what interventions prevent issues. Cross-functional collaboration between development, operations, security, and finance teams maximizes monitoring value.
How Opsolute Simplifies Multi-Cloud Monitoring
Organizations struggling with multi-cloud visibility can benefit from unified platforms that consolidate monitoring across providers. Opsolute delivers real-time oversight spanning AWS, GCP through a single dashboard, eliminating the fragmentation that creates operational blind spots.
The platform's heatmap visualization reveals resource utilization patterns over time, making it simple to identify over-provisioned infrastructure wasting budget or under-utilized resources risking performance issues. Service topology mapping shows dependencies between cloud resources, clarifying how components interact across complex distributed systems.
Performance tracking monitors API success rates and response times, surfacing degradation before it impacts users. Combined with FinOps capabilities including anomaly detection, forecasting, and intelligent showback, teams gain both operational and financial visibility from one solution.
By integrating cost optimization directly with performance monitoring, Opsolute helps organizations balance efficiency with effectiveness rather than optimizing one at the expense of the other.
Frequently Asked Questions
What is cloud monitoring and why is it important?
Cloud monitoring continuously observes infrastructure, applications, and services to ensure optimal performance, security, and cost efficiency. It's critical because it detects issues before they impact users, optimizes resource utilization, maintains security compliance, and controls spending across distributed environments.
What are the key metrics to track in cloud monitoring?
Essential metrics include CPU and memory utilization, network latency and bandwidth, application response times and error rates, storage IOPS and throughput, security incident counts, uptime percentages, and cost per resource or department. These metrics provide visibility into performance, reliability, security, and financial efficiency.
How is cloud monitoring different from traditional IT monitoring?
Cloud monitoring addresses distributed architectures across multiple providers, dynamic resource scaling, shared responsibility models, and API-based data collection. Unlike traditional monitoring focused on static infrastructure, cloud monitoring handles ephemeral resources, serverless computing, containers, and multi-tenant environments with vendor-specific tools and metrics.
What challenges do organizations face with multi-cloud monitoring?
Major challenges include fragmented visibility across providers, inconsistent APIs and data formats, alert fatigue from multiple tool sets, integration complexity, high monitoring costs, difficulty correlating data from diverse sources, and maintaining security across heterogeneous environments without unified platforms.
How does AI improve cloud monitoring?
AI enhances monitoring through automated anomaly detection identifying unusual patterns, predictive analytics for capacity planning, intelligent alert correlation reducing noise, automated remediation workflows, and behavior-based threat detection. These capabilities help teams shift from reactive firefighting to proactive issue prevention.
What is the ROI of implementing effective cloud monitoring?
Organizations achieve measurable returns through reduced downtime (up to 79% improvement with full-stack observability), optimized spending (identifying 15-30% cost savings through idle resource detection), improved developer productivity, faster incident resolution, enhanced security posture, and better compliance. Studies show observability delivers a 4x median ROI, with mature implementations achieving even higher returns.
How can I reduce alert fatigue in cloud monitoring?
Combat alert fatigue by setting meaningful thresholds based on business impact, implementing intelligent alert correlation, using AI-driven anomaly detection, establishing clear escalation procedures, regularly reviewing and tuning alert rules, consolidating to unified platforms, and focusing on actionable alerts requiring human intervention.
What should I look for in a cloud monitoring tool?
Key features include multi-cloud support for AWS, Azure, and GCP, real-time data collection and visualization, customizable dashboards, intelligent alerting and automation, comprehensive metric coverage, easy integration with existing tools, cost tracking capabilities, security and compliance monitoring, scalability, and vendor-agnostic architecture preventing lock-in.
Ready to gain unified visibility across your multi-cloud infrastructure? Schedule a personalized demo to discover how Opsolute delivers real-time monitoring, intelligent cost optimization, and proactive issue detection from a single platform.
Stop guessing what your AWS bill will be next quarter.
Connect your AWS Organization in under 30 minutes. Most customers see their first chargeback report in 14 days and realize a 5–10× return on Opsolute within 90 days.
